Lei Fengwang: According to Dalong, the author of this article has graduated from the Computing Technology Research Institute of the Chinese Academy of Sciences in July 2011. He was a senior research and development engineer at the Baidu Deep Learning Institute (IDL), and received the highest Baidu award—the Million Dollar Award twice in a row; Now Horizon Robotics is responsible for the research and development of autonomous algorithms for robots, smart homes, and toys. It involves deep learning, computer vision, human-computer interaction, SLAM, and robot planning control.
Deep learning leads the way Deep learning in the field of artificial intelligence dominates the field Since Geoffery Hinton and others published their famous paper in the journal Science in 2006, the boom in deep learning has swept from the academic world to the industrial world.
From that day onwards, the application of deep learning in the industrial world is in full swing, and it is truly beginning to “deep†influence our lives. For example, this big cow student participated in the development of the earliest CDNN-based image recognition technology in China, which greatly enhanced the effects of computer vision-related online applications. It also led innovative research and development of CNR and BLSTM-based OCR recognition systems. The recognition rate of commercial OCR system, his work has affected millions of Internet users including you and me.
One of the characteristics of artificial intelligence is the ability to learn, that is, whether the performance of the system will continue to increase with the accumulation of empirical data. We recognize that deep learning has great advantages in the following three aspects:
1. From a statistical and computational point of view, deep learning is particularly suitable for processing big data. On many issues, deep learning is the best method we can find.
2. Deep learning is not a black box system. It provides a rich set of connectivity-based modeling languages ​​(modeling frameworks). Using this set of language systems, we can express the inherent rich relationships and structures of data, such as the use of convolutions to process two-dimensional spatial structures in images, and the use of Recurrent Neural Networks (RNN) to process temporal structures in natural language and other data. .
3. Deep learning is almost the only end-to-end machine learning system. It directly acts on the original data and automatically performs feature learning layer by layer. The entire process directly optimizes an objective function.
A Record of Technical Sharing on Site Learning About Field Learning's Technology Sharing Field Record Starting from the ImageNet competition in 2012, deep learning first played a huge role in the field of image recognition. As the research progressed, deep learning was gradually applied to audio, video, and natural language understanding. The characteristic of these fields is the modeling of time series data, which we call Sequence Learning. How to use the deep learning to carry out end-to-end learning, and to abandon the intermediate steps based on artificial rules, in order to enhance the effectiveness of Sequence Learning has become a hot topic of current research.
Sequence Learning has been successfully applied to many fields, such as speech recognition, image captain, machine translation, OCR, etc. Their common feature is to use DNN or CNN to extract high-level semantic features and use RNN to model temporal information. In terms of loss function, in addition to the usual loss of logistic, structural loss was also introduced, such as the loss of sequence-to-sequence sequences such as CTC.

Variations of simple RNN—LSTM

CTC structured loss function
In Sequence Learning, we believe that the structural loss function associated with RNN and sequence is an important part of the current success of timing learning. In addition to the traditional simple RNN, there have been many RNN variants, such as LSTM (Long Short Temporal Memory), GRU (Gated Recurrent Unit), etc., which have been widely applied to the task of timing learning. They all have specific Recurrent structures. And the long-term information modeled by a series of gate switches adaptively overcomes the problem of gradient disappearance or explosion in the Simple RNN optimization process to some extent. As a structural loss function, CTC does not need to segment the sequence data and estimate the overall sequence labeling probability as a loss. It has been widely applied to OCR, speech recognition and other sequence identification tasks.
Here he uses OCR as an example to introduce how to use machine learning, especially Sequence Learning technology, to upgrade the traditional OCR technology.
End-to-end sequence learning

Daniel is explaining RNN on a whiteboard
The concept of optical character recognition was proposed as early as the 1920s, and has always been an important topic in the field of pattern recognition.
The classic optical character recognition system from the input image to the output of the final text recognition results, through layout analysis, line segmentation, word segmentation, single word recognition, language model decoding and post-processing. The technologies involved are divided into two broad categories based on empirically-developed rules and statistical learning-based models. The former includes the binarization of the system preprocessing stage (layout analysis, line segmentation, word segmentation), connectivity analysis, projection analysis, etc., as well as the regular noise filter in the post-processing stage; the latter includes class-based gradient histograms (Histogram). Of Oriented Gradient, HOG) feature-based word recognition engine and N-gram based language model for single-word recognition and language model decoding.
Under the condition of simple data and controllable conditions, the classical optical character recognition technology architecture can achieve more ideal identification accuracy through careful manual rule formulation and appropriate model parameter learning. However, in a wide range of natural scenes, the complexity of the image information presented by the text is significantly increased, and the conditions for shooting the image are not well controlled. The classical optical character recognition technology architecture is difficult to meet the needs of practical applications. The reason is that the process of this technical architecture is cumbersome and lengthy, leading to continuous transmission of errors, as well as excessive reliance on manual rules and disregard for large-scale data training.
solutionIn view of the characteristics of complex scenes and the deficiencies of the classical technology framework, the use of machine learning, especially Sequence Learning technology, has significantly transformed the system process and technical framework of optical character recognition.

In the aspect of system flow, the traditional rule-based methods such as binarization and connectivity are abolished, and the concept of Boosting text detection based on learning is introduced, and the line segmentation is merged into a new preprocessing module. The task is to detect the area containing text in the image. Generate corresponding text lines; combine word segmentation and word recognition into a new full-line identification module; N-gram-based language model decoding module is retained, but will mainly rely on manual rule layout analysis and post-processing module to remove from the system . The six steps are reduced to three steps, reducing the adverse effects of error transfer.
In addition, since the entire line of text recognition is a sequence learning problem, we have specifically developed a learning algorithm based on a Bidirectional Long Short-term Memory (BLSTM) recurrent neural network sequence model. The image features extracted by the convolutional neural network model do not consider the specific location of each character, but only the text content corresponding to the entire image sequence, so that the single word segmentation and single word recognition problems are integrated, and the deep learning theory is finally pursued. Ideal - end-to-end training.

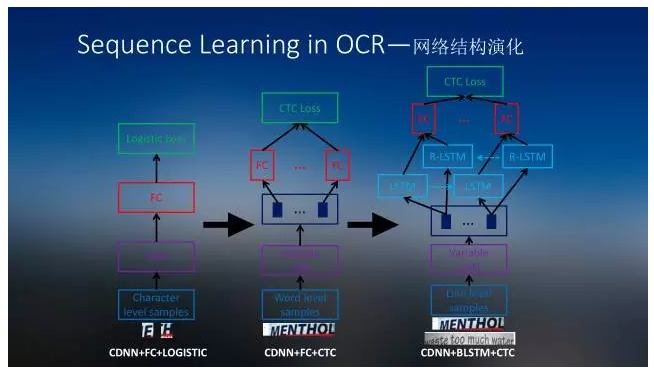
Doing so can make full use of contextual context disambiguation to avoid irreversible errors caused by character segmentation in traditional methods. This sequence-learning model is extremely good at identifying difficult-to-separate word sequences, even including scribbled handwritten phone numbers. In addition, this sequence learning model also makes it difficult to label the training data, which facilitates the collection of larger training data. Different languages ​​(even if the length and structure of words and sentences are very different), the problem of optical character recognition can also be integrated into the same technical framework to solve the problem, significantly reducing system maintenance costs.

As practitioners of deep learning and Sequence Learning, we have gained many valuable experiences and knowledge:
1. Abundant image disturbance is an effective means for us to apply prior knowledge about the image to the input of deep learning. Unlike many other data, images and videos have good continuity and structure in the temporal and spatial dimensions, and contain a large amount of redundant information. Whether translation and flipping, rotation, scaling, Gaussian, salt-and-pepper noise, and erroneous image processing transformations, a large amount of effective training data can be generated to enhance the robustness of the deep learning model.
2.RNN as a modeling language for sequence information can effectively model the dependencies within the sequence. The RNN can use its internal memory to process input sequences at any timing, which greatly reduces the difficulty of sequence modeling in video processing, speech recognition, and semantic understanding.
3. The structured loss function is an effective way to use modeled knowledge for deep learning output. When the artificial model is used to post-process the output of the deep learning model, the targeted structured loss function can often help the deep learning process converge to a more ideal state more quickly.
Looking into the future, based on the deep learning sequence identification problem, we can focus on the following focus:
Enhanced learning
Compared with convolutional neural networks and recursive neural networks, models that enhance learning outcomes can generate input sequences more flexibly based on the characteristics of the data, and train the model in a more vaguely supervised manner. In this way, the complexity of the model can be streamlined, and the speed of prediction can be improved. At the same time, the difficulty of labeling training data can be greatly reduced, so that the learning and prediction process does not require excessive manual participation and is closer to a truly intelligent learning mode.
Attention modelAttention
As an abstract concept, it simulates people's recognition behavior. It not only uses the status information at the current moment of the sequence, but also performs adaptive modeling weighting on the previous sequence state information during the decoding process, thereby making use of the context. The full information.
Lei Feng network (search "Lei Feng network" public number concerned) : This article is authorized by the horizon robot authorized Lei Feng network, for reprint please contact the original author.