(Original title: Berkeley AI Labs blog releases the first article: Let neural networks choose their own modules for dynamic reasoning)
Although deep neural networks have achieved great success in images, speech, and robots, these successes are usually limited to recognition tasks or generation tasks. Conventional neural networks are usually powerless for reasoning tasks. The Berkeley AI Lab recently opened a blog. The first article of the blog focused on reasoning tasks and proposed a neural module network. Through the training of multiple neural network modules to complete inference tasks, each neural network module is responsible for a reasoning step. Inference tasks dynamically combine these modules to generate new network structures for different problems.
The author of the article is Jacob Andreas. Lei Fengnet learned that he is a fourth grade Ph.D. student in the NLP at Berkeley and a member of the BAIR Lab. The introduction on his personal home page reads, "I hope to teach computer reading." The research direction includes machine learning models and structured neural network methods. At the same time, he is also a high-producer of thesis, and this year alone there were many papers selected for mainstream international top academic conferences such as ICML, ACL, and CVPR. Lei Fengnet translated the first paper he published. The full text is as follows:
Introduction of the problem
Suppose we are building a home robot and hope it can answer questions about the surrounding environment. We may ask him these questions:

How to ensure that the robot can correctly answer these questions? The standard method for deep learning is to collect a large number of questions, images and answers as data sets, train a single neural network, and map questions and images directly to answers. If most of the questions look like the problem on the left, we already have similar solutions for image recognition problems. These single methods are very effective:
But for the right question, this single neural network is hard to work with:
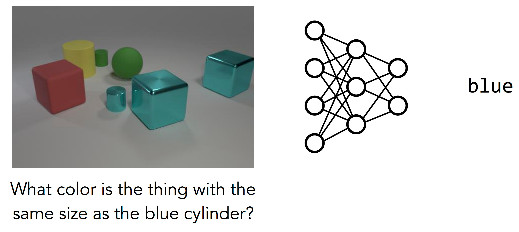
The single network trained here has been abandoned, and guessing gives the most common colors in the image. What makes this problem more difficult than the previous one? Even if the image is clearer and concise, the problem still requires many inference steps: the model must first find the blue cylinder, find another object of the same size, and then determine its color, instead of simply identifying the main object in the image. This is a complex calculation, and the complexity of the calculations is closely related to the issues raised. Different problems require different steps to solve.
The main paradigm in deep learning is a “one size fits all†approach: design a fixed model architecture for any problem that needs to be solved, hoping to capture all relationships between input and output, and learn the model from calibrated training data The various parameters.
But real-world reasoning does not work in this way: it involves a variety of different capabilities, and different capabilities are combined in new ways to solve every new challenge we face in the real world. What we need is a model that can dynamically determine how to reason about the problems that lie ahead of it—a network that can choose its own structure. Researchers at Berkeley AI Lab have addressed this issue by presenting a model called the Neural Module Network (NMN) that incorporates this more flexible solution into the problem solving process while retaining Deep learning effective features.
How to solve
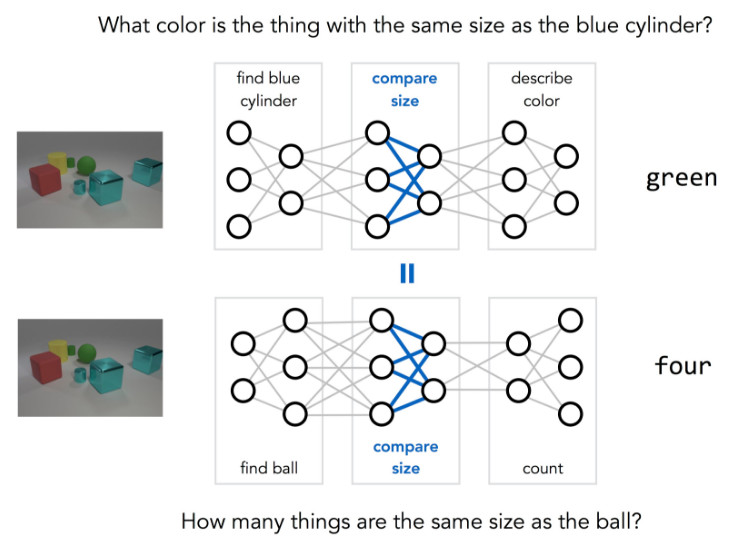
The reasoning problem mentioned above involves three different steps: find a blue cylinder and find other objects of the same size to determine its color. According to the reasoning process, the following figure can be drawn:

A different question may involve different steps. If the question is "How many things have the same size as the ball?" you can get the following inference steps:

Some basic operations, such as "compare sizes," are shared across different issues, but they may be used in different ways. The key idea of ​​MNM is to clarify this type of sharing: use two different network structures to answer the above two questions, but implement shared weights between networks that involve the same basic operations.
How to learn for such a new network structure? In fact, the researchers simultaneously trained a large number of different networks and tied the parameters together when appropriate, instead of training a single large network through many input/output pairs.
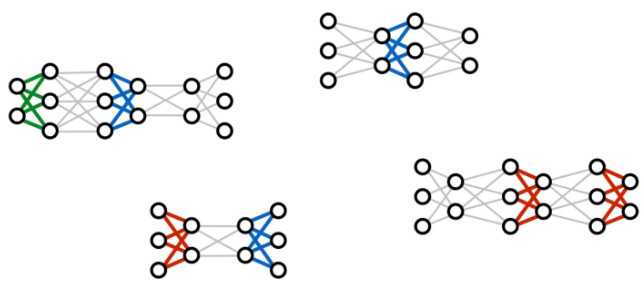
The picture above shows several common deep learning network structures, including DyNet and TensorFlow Fold. By combining them dynamically, different reasoning tasks can be completed.
What is acquired at the end of the training process is not a single deep network but a collection of neural "modules" each of which implements a step of reasoning. When it is desired to use a trained model on a new problem instance, researchers can dynamically combine these modules to generate a new network structure for the problem.
One thing worth noting about this process is that there is no need to provide any low-level oversight for individual modules during training: the model never sees blue objects or isolated instances of "left" relationships, and modules can only be larger Learning in the compositional structure, only the (problem, answer) pairs are supervised, but the training program can automatically infer the correct relationship between the structural component and its responsible calculation:
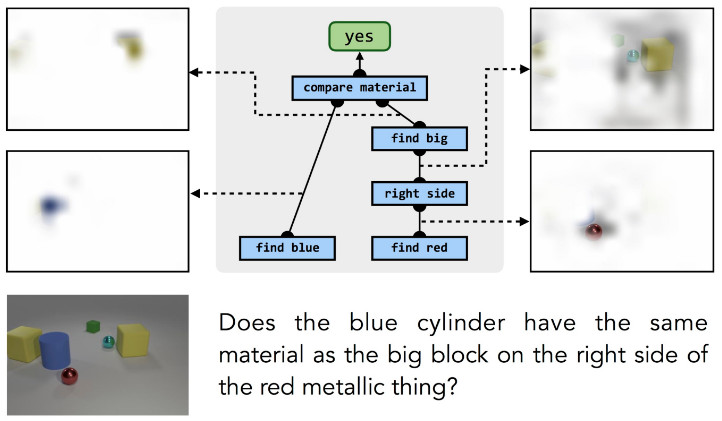
The same process can also answer questions about realistic pictures and even answer questions from other sources of knowledge, such as databases:
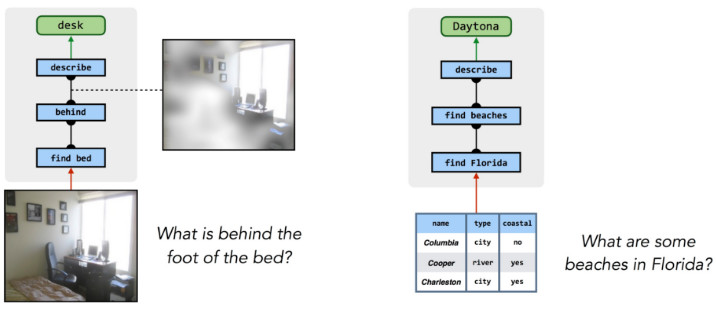
How to get an inference blueprint from a problem
The key element of this entire process is the collection of advanced "blueprints for inference" as above. These blueprints tell us how each issue's network should be laid out and how different issues relate to each other. But where do these blueprints come from?
In a preliminary study of the models in Refs. 1 and 2, the researchers found an astonishing connection between the design of a neural network of specific problems and the analysis of grammatical structures. Linguists have long believed that the grammar of a problem is closely related to the sequence of calculation steps required to answer it. Due to recent advances in natural language processing, off-the-shelf parsing tools can be used to automatically provide an approximate version of these blueprints.
However, the accurate mapping from the language structure to the network structure is still a challenging issue and it is easy to make mistakes in the conversion process. In later work, researchers turned to the use of data produced by human experts who directly annotated a series of questions with an idealized reasoning blueprint without relying on linguistic analysis. By learning to imitate these human experts, the model can greatly improve the quality of predictions. The most surprising thing is that when trained models are used to imitate experts, but they are allowed to modify the predictions of these experts themselves, it can find better solutions than experts in different problems.
to sum up
Despite the remarkable success of deep learning methods in recent years, many problems remain a challenge, such as few-shot learning and complex reasoning. These problems are where architectural classic methods shine, such as semantic analysis and program induction. The neural module network combines the advantages of both the classic artificial intelligence method and the deep learning method: the flexibility of the discrete combination and the high efficiency of the data, combined with the characterization power of the deep network. NMN has been successful in many visual and textual reasoning tasks. At the same time, researchers are also trying to apply this method to more AI tasks.