Speech recognition is a high-tech technique in which a machine converts a speech signal into a corresponding text file or command through a recognition and understanding process. As a specialized research field, speech recognition is an interdisciplinary subject, which is closely related to many disciplines such as acoustics, phonetics, linguistics, digital signal processing theory, information theory, and computer science. After more than 40 years of development, speech recognition has shown great application prospects. This paper starts with the implementation principle and introduces the implementation of the speech recognition system.
1 Overview
The Chinese speech recognition system is a non-specific, isolated speech speech recognition system. The isolated sounds include at least 400 tuning syllables in Chinese (without regard to tone) and some commonly used phrases. The identification system is mainly used for handheld devices such as mobile phones and PDAs. The CPU of these devices is generally DSP, the hardware resources are very limited, and most of them do not support floating-point operations. Then, the primary consideration for the design of the various parts of the system is that the overhead of the system for hardware resources must be as small as possible and cannot exceed the limits of these devices. The overhead of hardware resources includes the overhead of storing model parameters and the overhead of memory and DSP runtime during the identification process.
2 implementation process
The general voice processing flow chart is shown in Figure 1.
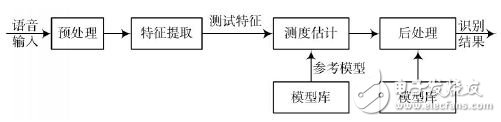
Figure 1 Processing flow diagram of speech recognition system
In the speech recognition system, the analog speech signal becomes a digital signal after the A/D conversion is completed, but the speech signal in the time domain is difficult to be directly used for identification. Therefore, it is necessary to extract the characteristics of the speech from the speech signal, and on the other hand, The essential characteristics of speech, on the other hand, also play a role in data compression. The input analog speech signal is first pre-processed, including pre-filtering, sampling and quantization, windowing, endpoint detection, pre-emphasis, and so on. The model of the speech recognition system usually consists of two parts: the acoustic model and the language model, which correspond to the calculation of the speech to semi-syllable probability and the calculation of the semi-syllable to word probability.
3 feature extraction
At present, the general feature extraction method is based on a speech frame, that is, the speech signal is divided into a plurality of overlapping frames, and speech features are extracted for each frame. Since the sampling rate of the speech library used in the technical solution is 8 kHz, the frame length is 256 sampling points (ie, 32 ms), the frame step size or the frame shift (that is, the length of each frame speech does not overlap with the previous frame speech). ) is 80 sampling points (ie 10 ms).
The two main voice features used in existing speech recognition systems include:
Linear Predic TIon Cepstrum Coefficient (LPCC), which is based on the assumption that the speech signal is an autoregressive signal, and uses the linear prediction analysis to obtain the cepstrum parameters. The advantage of the LPCC parameter is that the calculation amount is small, and the vowel has a good description ability, and the disadvantage is that the description ability of the consonant is poor, and the anti-noise performance is poor.
Mel Frequency Cepstrum Coefficient (MFCC), which takes into account the auditory characteristics of the human ear, converts the spectrum into a nonlinear spectrum based on the Mel frequency, and then converts it to the cepstrum domain. Since the human auditory characteristics are fully simulated and there are no premise assumptions, the MFCC parameters have recognition performance and anti-noise ability. Experiments prove that the performance of MFCC parameters in Chinese digital speech recognition is significantly better than LPCC parameters, so this technical scheme adopts MFCC parameters. For speech feature parameters.
The general process of finding MFCC parameters is:
After the Hamming window is added to the input speech frame, a Fast Fourier Transform (TI) is performed to convert the time domain signal into a frequency domain signal.
Convert the linear frequency scale to the Mel frequency standard. The conversion method is to pass the frequency domain signal through 24 triangular filters, wherein the center frequency is 12 or more at each of 1 000 Hz and below. The center frequency spacing of the filter is characterized by a linear distribution below 1000 Hz and a geometric ratio distribution above 1 000 Hz. The output of the triangular filter is:
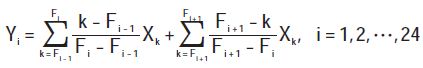
Where: Xk is the energy of the kth spectral point on the spectrum; Yi is the output of the ith filter; Fi is the center frequency of the ith filter.
Transform the filter output to the cepstrum domain using Discrete Cosine TransformaTIon (DCT):
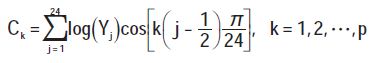
Where: p is the order of the MFCC parameters, where p = 12.{Ck}k = 1,2,...,12 is the MFCC parameter sought.
In order to reflect the dynamic characteristics of speech, a first-order differential cepstrum is added to the speech feature, and the calculation method is as follows:
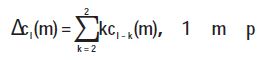
Where subscripts l and l - k denote the lth and l - k frames; m denotes the mth dimension.
The main point of MFCC parameter calculation is to convert the linear power spectrum S(n) into a power spectrum at the Mel frequency. This requires setting several bandpass filters Hm(n) in the spectral range of the speech before calculation, m=0. , 1, 2, ..., M - 1, n = 0, 1, 2, ..., N/2 - 1. M is the number of filters, and N is the number of points of a frame of speech signal. Each filter has a triangular nature with a center frequency of fm, which is evenly distributed over the Mel frequency axis. At linear frequency, the adjacent fm interval is small when m is small, and the adjacent fm interval is gradually opened as m increases. The conversion relationship between Mel frequency and linear frequency is as follows:
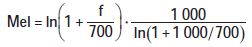
The parameters of these bandpass filters are calculated in advance. Figure 2 shows the distribution of the filter bank, where M is chosen to be 26, the number of FFT points N is 256, and the sampling frequency of the speech signal is 8000 Hz.
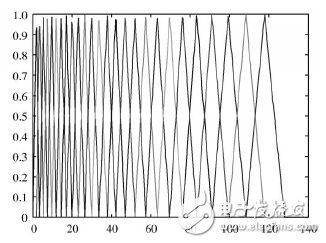
Figure 2 Mel-scale filter bank designed using human ear bionics
UK Surface Tabletop Socket be with American type plug,could be selected to be with USB ports,Internet ports,Phone ports,overload protection and with or without switch.
US Surface Tabletop Socket can be set into furniture and office furniture like table,cabinet and so on.It will be easily to use the charging for Phone and home appliance.
Specifically, We have our own design and production team for USB Circuit Board design and produce.
US Surface Tabletop Socket
Power Outlet Strip,USSurface Tabletop Socket,USA Surface Mounted Power Strip,USSurface Mounted Power Strip
Dongguan baiyou electronic co.,ltd , https://www.dgbaiyou.com